
Homeschool Memories
[Based on a problem I made up for my co-op students, once upon a time…]
Conversion factors are special fractions that contain problem-solving information. Why are they called conversion factors?
- “Conversion” means change, and conversion factors help you change the numbers and units in your problem.
- “Factors” are things you multiply with. So to use a conversion factor, you will multiply it by something.
For instance, if I am driving an average of 60 mph on the highway, I can use that rate as a conversion factor. I may use the fraction:

Or I may flip it over to make:
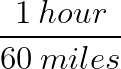
It all depends on what problem I want to solve.
After driving two hours, how far have I gone?
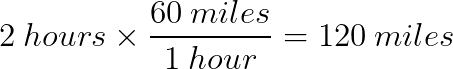
But if I am planning to go 240 more miles, how much longer will it take?
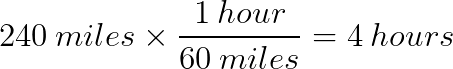
Any rate can be used as a conversion factor. You can recognize them by their form: this per that. Miles per hour, dollars per gallon, cm per meter, and many, many more.
Of course, you will need to use the rate that is relevant to the problem you are trying to solve. If I were trying to figure out how far a tank of gas would take me, it wouldn’t be any help to know that an M1A1 Abrams tank would get about 1/3 mile per gallon. I won’t be driving one of those.
Continue reading Conversion Factors: How Old Are You in Nanoseconds?










